.
Egy érdekes tárgybeli éles projekt DEMO-verziójának leírása következik alább, természetesen anonimizált adatokkal, de meghagyva az "éles kontextust".
FELADAT:
Adva van egy ETL-eszköz (egyébként TALEND), ami mindenféle job-ok révén adatot tölt adatbázisokba.
LEÍRÁS, SCREENSHOT-okkal :
Miért érdekes a téma, hogy blogposztot szánok neki?
- Mert megmutatja (szvsz) a vizualizálás hihetetlen erejét: komplex Tableau-kalkulációk, dashboard, action filter, minden haladó üzleti intellgiencia hókusz-pókusz
NÉLKÜL is.
- Mert ingyen (hiszen lehet-e létezni Tableau nélkül egy enterprise kategóriájú business-ben :), pár kattintással, sok embernek ad konszenzusos információt.
Adatokról:
- Vannak tehát JOBGROUP-ok
- Amik futásilag elindulnak (opcionálisan periodikusan)
- Kézzel vagy automatikusan
- Hétközben vagy hétvégén
- Tartanak valameddig
- Van nekik státuszuk
- Van nekik futási idejük
- Végül, de nem utolsó sorban vagy teljesítik az SLA-t (=Service Level Agreement), vagy nem.
- Futó JOBGROUP-ok esetén meg különböztetődnek az "in progress" meg "pending" job-ok. Az előbbi jó ("futhat"), az utóbbira lehet, hogy rá kell nézni. Minden JOB-nak van előélete (futott már korábban), ha vesszük a MAXIMÁLIS futásidőt, ezt szorozzuk egy konstanssal (pl.: 0.9-cel), akkor ez lehet egy küszöbérték, ami alatt "in progress", ami felett "pending"-nek vesszük az adott JOBGROUP-ot.
Mikor "jó" az ábránk, értve ezalatt, hogy a menedzser nyugodtan issza meg a kávéját, miután rátekintett.
- Minden automatikus JOBGROUP elindult
- Lefutott
- Sikeresen futott le minden
- Nem volt megelőzően sikertelen futás
- Belül van a futás vége az SLA-nak
- Futó JOBGROUP, ha van akkor "in progress"
Az igazi "real-life" projekt persze komplexebb volt:
- Voltak JOB-ok, JOBGROUP-okba szervezve (hierarchikusan)
- Voltak fontosabb és még fontosabb JOB-ok/JOBGROUP-ok
- Volt, hogy ebédtől(12:00) ebédig is kellett ábrázolni a napokat.
- Voltak effektív hibaüzenetek
- Voltak contextek
- A TALEND-logokat előemészteni, adatgazdagítani kellett
- stb.
Nem lehet célom a teljes projekt bemutatása egy ilyen blogposztban, még ez a maximálisan könnyített verzió sem lesz rövid.
1.
Ahogy megbeszéltük az elején, van egy kész "DEMO" adatforrásunk, a szükséges adatokkal (esetünkben 80.000+ rekorddal)
.
2.
Nézzünk bele az adatokba.
Rögtön az első oszlopnál (day_of_week), a WE(=WeekEnd) mutatja, hogy az adott nap hétvége-e.
A start_hours_minutes a 4:30-at 4.5-re konvertálja (60-as számrendszerről 10-esre áttérés)
.
3.
"Start Time" oszlopot konvertáljuk "CONTINUOS-ra"
.
4.
Ugyanígy az "End Time" oszlopot is konvertáljuk "CONTINUOS-ra"
.
5.
Válasszuki a "GANTT-diagrammot".
Az elképzelés az, hogy a vízszintes tengelyen lesznek a napok, függölegesen az órák [0-24]
Lesznek téglalapocskáink a töltésekre (adott napon mettől meddig tartott egy töltés)
.
6.
Vonszoljuk fel drag and drop-pal a "COLUMNS"-ba, a "DIMENSIONS"-ök közül a "DAY_OF_WEEK"-et. A színe automatiksuan kék lesz a "DIMENSIONS" miatt.
.
7.
Ugyamígy vonszoljuk fel a "ROWS"-ba a "MEASURES" -k közül a "START_HOURS_MINUTES"-t. A színe automatiksuan zöld lesz a "MEASURES" miatt.
.
8.
Mivel a "START_HOURS_MINUTES"-t measure-ként ismerte fel a Tableau (ennek aggregálási hátrányaival), konvertáljuk DIMENSION-né.
.
9.
Vonszoljuk a "MESSAGE_IMPORTANT_JOBGROUP" dimenziót a "COLOR"-ra (ott balközép tájon).
A dimension-név mellett megjelent a jellegzetes, "COLOR"-specifikus ikon.
Nyilván szinesben szeretnénk látni, hogy sikeres-e vagy sem egy JOB-futás.
Kezd alakulni a vizualizációnk, megjelentek a várva-várt téglalapocskák, ráadásul színesen :)
.
10.
A Tableau default-ban "ZÖLD"-re rakta a "sikeres"-ket (ami jó), de a "sikerteleneket" "KÉK"-be. Ezért az utóbbi módosítsuk "PIROS"-ra
.
11.
Ki kell jelölni a "FAILURE"-t, majd lehet a "PIROS" négyzetre klikkelni.
.
12.
Rögtön jobban elüt a sikeres töltés a sikertelentől :)
.
13.
Vonszoljuk fel a "DURATION_IN_HOUR" measure-t a "SIZE"-ba.
Nyilván egy téglalap annál hosszabb. minél tovább tartott a futás idő.
A measure-név mellett megjelent a jellegzetes "SIZE"-specifikus ikon.
.
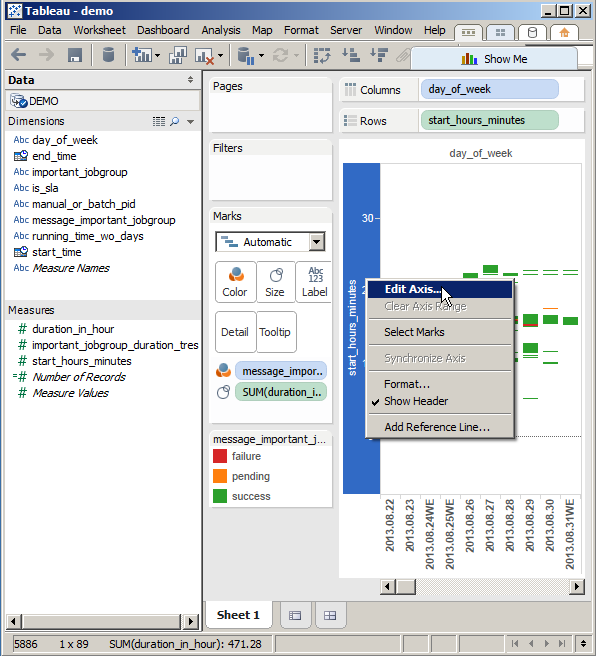
14.
Formázzuk meg a függőleges tengelyt.
.
15.
Ne automatikus legyen, nem szimpatikus értékekkel
.
16.
Hanem "FIXED", elvégre egy napban mindig konstansan 24 óra van. :)
.
17.
A skálázás se default automatikus legyen
.
18.
Hanem félórás léptékű.
Ez még nem túl sok, de már elég finom felbontás
.
19.
Gyönyörködhetünk a frissen elkészült függöleges tengelyben.
.
20.
Jöhet a vízszintes tengely
Én elfordítottam "ROTATE"-tel 90%-kal a napokat (default beállítással szemben), hogy több napot lehessen egybe látni.
Mivel a napok végén van a "WE", ha hétvégére esik, így azonnal szembeszökik, hogy melyik nap hétvége.
Nyilván kérdés, hogy a WE hol mutat jobban, a dátum elején (szintbehozva a dátumokat) avagy a végén. Ez ízlés kérdése, nekem így tetszett jobban :)
Nyilván szebb lenne, ha a tengelyen szinezni lehetne a napokat, de ez kulturáltan nem kivitelezhető a Tableau jelenlegi 8.0-s verziójában. Valami ígéret van, hogy 8.1-ben lesz előrelépés ez ügyben is.
.
21.
Most már jöhet a diagram formázása.
.
22.
Nyilván szeretnénk valamiféle GRID-et, hogy jobban vezetődjék a szemünk.
A gridnek van vonaltípusa, vonalvastagsága, vonalszíne.
Külön felhívnám a figyelmet, hogy ezt a várakozásokkal ellentétben, nem a "GRID"-ikonra kattintva lehet beállítani, hanem a "LINES"-nál ;)
.
23.
Egyre inkább alakul :)
.
24.
Természetesen (quick)filterek nélkül nem élet az élet.
Vonszoljuk fel az "IMPORTANT JOBGROUP"-ot a filterek közé
Válasszuk ki a "USE ALL"-t (hogy mindenből lehessen választani)
.
25.
Majd pipáljuk be a "SHOW QUICK FILTER-t"
.
26.
Lám jobb oldalon megjelent a kívánt quick filter. :)
.
27.
Helykímélésből nem ismétlem meg a screenshot-okat
A további mezők quick fitleresítése ugyanígy megy.
- MANUAL_OR_BATCH_PID
- MESSAGE_IMPORTANT_JOBGROUP
- IS_SLA
stb. (igény szerint)
.
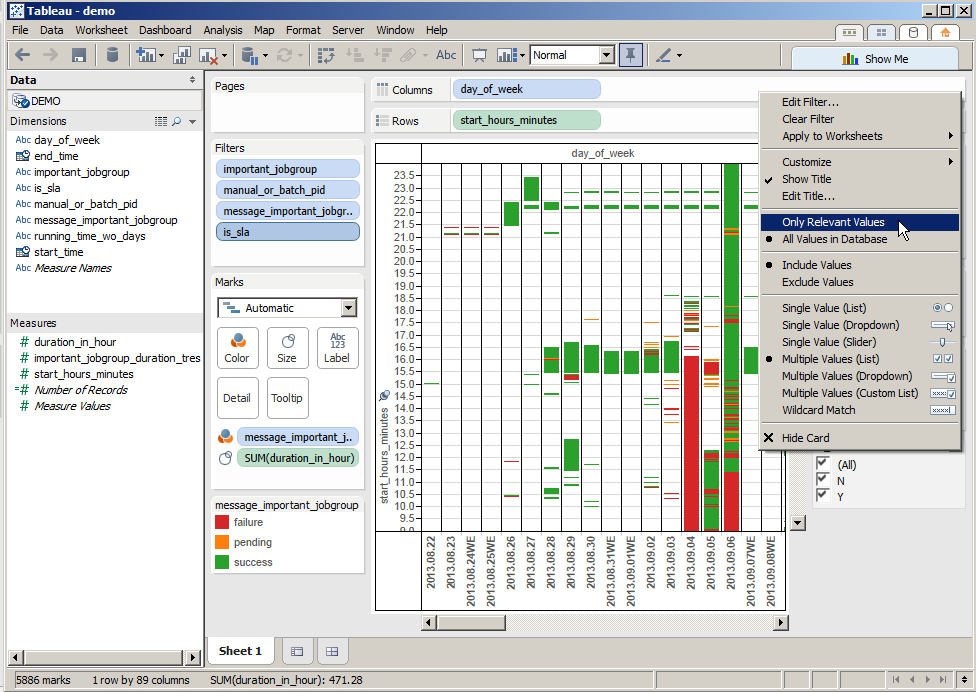
28.
Quick filtereknél lehet állítani, hogy "ONLY RELEVANT VALUES".
Ennek az az értelme, hogy mivel minden mindennel összefügg, lehet, hogy egy kattintás nyomán nem lesz az ábrán minden lehetséges érték - például csak sikeres futások találhatók adott kontextusban. :)
.
29.
Hátravan a téglalapocskák "TOOLTIP"-ezése
Ehhez elsőként a megjelenítendő adatokat vonszoljuk a "DETAIL"-be.
Elsőként az IMPORTANT_JOBGROUP-ot
.
30.
Majd:
RUNNING_TIME_WO_DAYS (00:00:00 formában mutatja a futási időt)
START_TIME-ot
.
31.
YEAR(START_TIME) defaultot , állítsuk "EXACT DATE"-re.
.
32.
Ugyanígy az END_TIME-nál is, ismételjük meg ezt.
.
33.
A TOOLTIP-re kettőt kattinva, notepad-szerűen szerkeszthetjük a TOOLTIP-et
.
34.
Sőt meg is nézhetjük "PREVIEW" -val mit alkottunk.
.
35.
Így néz ki a TOOLTIP élesben
.
36.
Mivel előbb-utóbb több napnyi adat lesz, mint ami egy képernyőre kifér, célszerű állítani, hogy csak az utolsó X nap látszódjék
.
37.
Ezt kell állítani hozzá
.
38.
És készen vagyunk.
Nyilván egyéni ízlés szerint lehet finomhangolni vizuális elemeket, egyebeket.
Az én főnököm például jobban szereti a rádiógombokat, míg én meg a checkbox-okat szeretem jobban, stb. :)
Vagy lehetne vízszintes referenciavonalat húzni az SLA-hoz, például reggel 8:00-hoz
A lényegen ez már nem változtat. ;)
Mit látunk?
Bár korábban volt rendesen sok piros, mostanra normalizálódott a helyzet, egyre több a zöld, egyre kevesebb a piros téglalap. Ráadásul mindegyik ugyanakkor indul automatikusan, nem kézzel kell hackelni, hibalehetőségekkel. Sőt a még a futási idők is hasonlítanak egymásra.
Mire nem jó egy vizualizáció ugye :)
.
Eddigi TABLEAU-blogposztjaim:
2013.06.17 - Data Science: Tableau-feladatok
2013.06.22 - Tableau: Egy vizualizációs stratégia lehetséges szubjektív sarokpontjai
2013-07-05 - Tableau: Mindennapi örömök
2013.07.09 - Tableau: Eset a NEM-létező egzotikus nagygépes adatpiaccal
2013.11.16 - Tableau: Aktuális Pros/Cons egyenleg
2013.11.17 - Tableau: Text Table
Ha valakinek még nincs meg a Tableau-szoftver, miközben
szeretne engedni a birtoklási csábításnak, az alábbi mail-címen egy
kedves, fiatal, aranyos kolléganő igyekszik hatékony és konkrét eszközök
segítségével ápolni minden Tableau-vonzatú kapcsolatot. Illetve biztos segít optimális árat találni a termékhez vezető rögös úton. :)
hello@tableausoftware.hu
.jpg)











































{kind=link}